Wir haben für MedCom labcomplete® einen KI-gestützten Parameterassistenten gebaut. Das System schlägt Ärzten bei der Laboranforderung passende Parameter vor – basierend auf medizinischem Kontext, Anforderungshistorie und Verrechnungsregeln. In diesem Post beschreibe ich die technischen Entscheidungen, die Architektur und was wir dabei gelernt haben.
Ausgangslage
Bei einer Laboranforderung wählt der Arzt aus hunderten möglichen Parametern. Welche davon sinnvoll sind, hängt von mehreren Faktoren ab:
Alter, Geschlecht und Fachgebiet des Arztes
Versicherungsstatus (nicht jeder Parameter ist bei jeder Versicherung abrechenbar)
Anforderungshistorie der letzten sechs Monate
Verfügbares Probenmaterial (bei Nachforderungen können nur bestimmte Parameter auf der bestehenden Probe laufen)
Dazu kommen Verrechnungsregeln, LOINC-Codes und Parameterunverträglichkeiten. Bei der Vielzahl an Parametern und deren oft kryptischen Kürzeln weiß der Arzt häufig gar nicht, was das Labor überhaupt anbietet und welche Parameter für seine Fragestellung relevant wären. Dieses Wissen steckt bisher in den Köpfen erfahrener Labormitarbeiter.
Genau hier setzt der Assistent an: Der Arzt gibt eine medizinische Fragestellung oder Symptome ein – z.B. „Verdacht auf Eisenmangel und Schilddrüsenfunktionsstörung“ – und erhält passende Parametervorschläge. Zu jedem Vorschlag liefert das System eine Begründung: welcher Parameter, warum er relevant ist und was er misst.
Was das System tut – und was nicht
Der Assistent ist in die bestehende Anforderungsoberfläche integriert und schlägt in Echtzeit Parameter vor. Er kennt alle verfügbaren Laborparameter inklusive LOINC-Codes, Synonyme und Verrechnungsregeln und berücksichtigt den Kontext der aktuellen Anforderung.
Wichtig: Das System ist kein Medizinprodukt. Es stellt keine Diagnosen und trifft keine medizinischen Entscheidungen. Die finale Auswahl liegt beim Arzt. Fragen außerhalb des definierten Scopes – z.B. „Hat der Patient Diabetes?“ – werden abgewiesen. Das Modell ist strikt auf Parametervorschläge beschränkt.
Modellwahl
Die Wahl des Sprachmodells war die Entscheidung mit dem größten Einfluss auf das Ergebnis.
Erster Versuch: Open-Source-Modell. Ergebnis:
Halluzinationen – das Modell hat Parameternamen erfunden, die nicht existieren, trotz gehärtetem System-Prompt
Medizinischer Kontext wurde oft ignoriert (Fachgebiet, Versicherungsstatus)
Time to First Token (TTFT) teilweise über einer Minute
Kein Token-Caching verfügbar
Für ein System, bei dem falsche Vorschläge Konsequenzen haben können, war das nicht tragbar.
Zweiter Versuch: Kommerzielles Modell über EU-gehosteten Managed Service. Ergebnis:
Keine Halluzinationen bei Parameternamen
Zuverlässiges Kontextverständnis
Time to First Token im niedrigen Sekundenbereich
Zuverlässiger strukturierter JSON-Output
Anforderung war, dass das Modell ausschließlich auf EU-Infrastruktur läuft. Direkte API-Aufrufe an US-Endpoints kamen nicht in Frage.
Die Token-Preise sind beim kommerziellen Modell höher als bei der Open-Source-Alternative – aber das zahlt sich aus: keine Halluzinationen, keine manuellen Korrekturen, keine Nacharbeit. Die Kosten liegen im Centbereich pro Anfrage. Vor allem Token-Caching hilft hier enorm – bei Multi-Turn-Chats wird der System-Prompt und Parameterkontext gecacht, was die Kosten bei Folgeanfragen deutlich reduziert.
Konkrete Anbieter- und Modellnamen nenne ich hier bewusst nicht – die ändern sich schnell, und die Erkenntnisse aus diesem Projekt sind unabhängig davon gültig. Entscheidend ist der Evaluierungsprozess, nicht das Label auf dem Modell.
Datenschutz
An das Sprachmodell gehen keine personenbezogenen Daten. Kein Name, keine Sozialversicherungsnummer, keine Adresse. Das Modell erhält ausschließlich anonymisierte Kontextdaten: Alter, Geschlecht, Versicherungsstatus. Die gesamte LLM-Kommunikation läuft über EU-Infrastruktur.
Sämtliche Patientendaten und kritischen Daten verbleiben auf unserer Exoscale-Infrastruktur in Österreich und werden zu keinem Zeitpunkt an den AI-Anbieter gesendet. Das Backend extrahiert vor dem LLM-Aufruf ausschließlich die anonymisierten Kontextdaten – alles andere bleibt auf Exoscale.
Das war von Anfang an so konzipiert, nicht nachträglich angepasst.
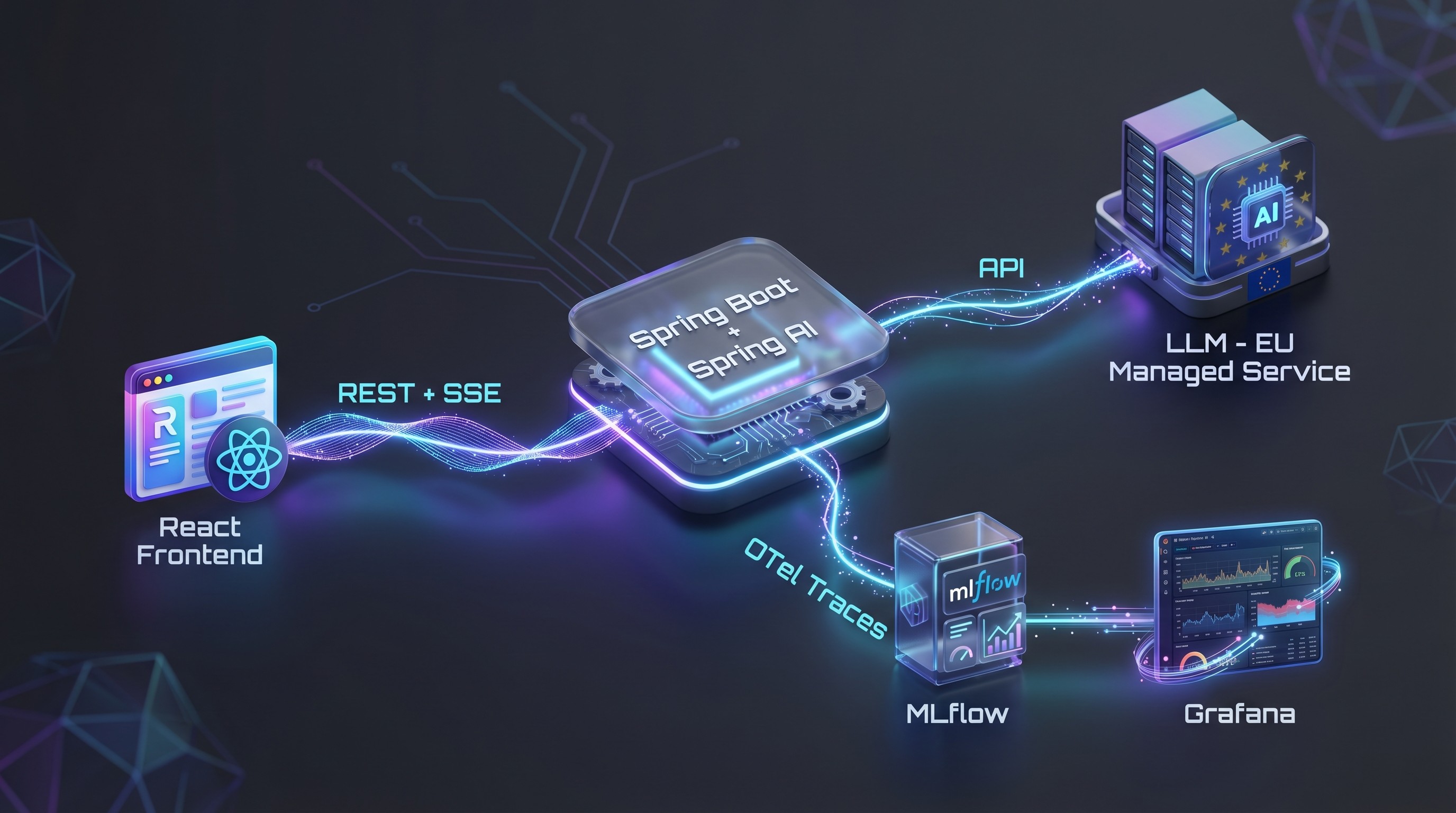
Architektur
Die wesentlichen Komponenten:
Frontend: React mit Ant Design X
Backend: Spring Boot mit Spring AI für die LLM-Anbindung
Streaming: Server-Sent Events – die Antwort wird in Echtzeit gestreamt
Rate-Limiting: Pro User, umgesetzt mit Redis
Feedback: Thumbs-Up/Down mit optionalem Freitext, wird in MLflow geschrieben
Observability: OpenTelemetry-Traces → MLflow + Grafana-Dashboard (Token-Verbrauch, Kosten pro Zuweiser, Latenz etc.)
Warum MLflow statt Langfuse?
Wir haben uns bewusst für MLflow und gegen Langfuse entschieden. Der Grund: Infrastruktur-Overhead. Langfuse benötigt im Self-Hosting-Betrieb Redis, PostgreSQL, ClickHouse und S3 – ein erheblicher Aufwand für Betrieb und Wartung. MLflow kommt für unseren Einsatzzweck mit einer einzigen PostgreSQL-Datenbank aus. Das passt zu unserem Prinzip, Komplexität nur dort einzuführen, wo sie einen klaren Mehrwert bringt.

Kontext statt RAG
Wir verwenden kein Retrieval-Augmented Generation. Pro Anfrage werden alle relevanten Parameter inklusive LOINC-Codes, Synonyme und AI-Beschreibungen in den Kontext gepackt. Das funktioniert durch ein komprimiertes, effizientes Format. Der Kontext besteht aus drei Ebenen:
Globaler System-Prompt
Laborspezifische Erweiterung des System-Prompts
Parameterspezifischer Kontext (Beschreibung, LOINC, Synonyme, Kurz-/Langbezeichnung)
Bei ca. 1.000 Laborparametern liegt der Kontext bei etwa 50.000 Tokens. Das passt komplett ins Kontextfenster – RAG war daher nicht nötig. Das hat die Architektur deutlich vereinfacht.

Qualitätssicherung mit automatisierten Evaluierungen
Wir haben eine automatisierte Eval-Pipeline aufgebaut:
Definierte Testszenarien mit erwarteten Ergebnissen
Automatisierte Tests gegen den Live-Endpunkt
Scorer validieren die Responses auf Korrektheit und Vollständigkeit
Model-as-a-Judge: Ein zweites Modell bewertet die Qualität
Alle Ergebnisse werden in MLflow versioniert und sind über Modellversionen hinweg vergleichbar
Der System-Prompt wurde über mehrere Iterationen optimiert, wobei jede Änderung automatisiert gegen die Eval-Suite getestet wurde.
Timeline
Vom Prototyp bis zur Produktion vergingen zwei bis drei Wochen:
Woche 1: Prototyp mit LLM-Anbindung, erste Eval-Szenarien
Woche 2: Streaming-UI, Feedback, Rate-Limiting, Observability
Woche 3: Beta-Rollout an ausgewählte Tester, Prompt-Feintuning mit echtem Feedback
Danach schrittweiser Rollout: Erst Beta-Tester, dann Freigabe an weitere Benutzer.
Was ich anders machen würde
Modell-Evaluation früher starten. Der Umweg über das Open-Source-Modell hat Zeit gekostet. Beim nächsten Mal würde ich das früher und breiter evaluieren.
Feedback-Loop früher einbauen. Echtes Nutzerfeedback ist extrem wertvoll – je früher es fließt, desto besser.
Observability vom ersten Commit. Wir haben den Token-Verbrauch pro Benutzer erst spät ins Monitoring aufgenommen. Bei einem System mit variablen Kontextgrößen (500 bis 1.000+ Parameter) sind die Kosten pro Anfrage nicht konstant – das muss man von Anfang an sichtbar machen, sonst fliegt es einem beim Rollout um die Ohren.
Fazit
Zwei bis drei Wochen vom Prototyp zur Produktion – das klingt schnell, war aber nur möglich durch sorgfältige Planung im Vorfeld. Die Architekturentscheidungen (kein RAG, kein Fine-Tuning, EU-only Hosting, MLflow statt Langfuse) standen fest, bevor die erste Zeile Code geschrieben wurde. Ohne dieses klare Bild hätten wir unterwegs ständig umgebaut.
Die wichtigsten Faktoren für den Erfolg: die richtige Modellwahl auf Basis systematischer Evaluation, Datenschutz als Architekturprinzip von Tag 1, automatisierte Evals als Sicherheitsnetz und der bewusste Verzicht auf unnötige Komplexität.


