Polyglottes Monorepo: Wie Nx, Mise, Pulumi und Exoscale zusammenspielen
Cloud & DevOps

Das Problem: 15 Repositories, ein Produkt
Man stelle sich vor: Eine B2B-Plattform, gewachsen über mehrere Jahre. Spring Boot APIs in Kotlin, React Frontends, Go-Services für Datenübertragung, Rust-Tools für Datenverarbeitung. Jede Sprache, jedes Modul – ein eigenes Repository.
Was anfangs übersichtlich wirkt, wird mit der Zeit zum Wartungs-Albtraum:
Dependency Hell: Ein Shared Library Update bedeutet Pull Requests in jedem Repository, das davon abhängt. Und in jedem muss separat getestet werden, ob die neue Version kompatibel ist.
CI/CD-Wildwuchs: 15 Pipelines, jede leicht anders konfiguriert. Wenn Pipeline 12 bricht, sucht man erstmal eine halbe Stunde, wo sie sich von Pipeline 3 unterscheidet.
Versionskonflikte: "Welche Version von
my-shared-libverwendet Service X?" – eine Frage, die niemand ohne Recherche beantworten kann. Und wenn zwei Services unterschiedliche Versionen verwenden, merkt man das erst in der Testumgebung.Onboarding-Aufwand: Neue Entwickler müssen erst verstehen, welche Repositories zusammengehören und wie sie miteinander interagieren. "Welches Repo muss ich für Feature Y klonen? Und welche anderen Repos brauche ich dafür auch noch?"
"Funktioniert auf meinem Rechner": Entwickler A hat Java 17, Entwickler B hat Java 21, der CI-Server hat Java 25. Alle drei haben unterschiedliche Ergebnisse.
Der naheliegende Einwand: "Ein Monorepo? Mit fünf verschiedenen Programmiersprachen? Das kann nicht funktionieren."
Es funktioniert. Und der Build ist schneller als vorher.
Warum Nx – auch für nicht-JavaScript-Projekte?
Nx wird oft als Tool für Angular- oder React-Monorepos wahrgenommen. Aber der Kern von Nx ist sprachagnostisch. Nx orchestriert nicht "JavaScript-Builds" – Nx orchestriert Tasks. Ein Task kann mvn package, cargo build oder go build sein. Nx ist es egal.
Die Stärke liegt in drei Konzepten, die unabhängig von der Programmiersprache funktionieren:
Task-Graphen: Nx versteht Abhängigkeiten zwischen Projekten. Wenn Service A von Library B abhängt, wird Library B automatisch zuerst gebaut. Das klingt trivial, aber bei 15 Projekten in 4 Sprachen mit gegenseitigen Abhängigkeiten wird die manuelle Orchestrierung schnell unmöglich.
Caching: Wenn sich an einem Projekt nichts geändert hat, wird es nicht neu gebaut. Nx berechnet einen Hash über alle relevanten Eingabedateien. Sind die Inputs identisch zum letzten Build, wird das Ergebnis aus dem Cache genommen – in Millisekunden statt Minuten.
Affected Detection: Bei einem git push werden nicht alle 15 Projekte gebaut, sondern nur die, die von den Änderungen tatsächlich betroffen sind. Ändert sich nur das Frontend, bleibt der Spring Boot Server in Ruhe.
In der Praxis bedeutet das: Egal ob Kotlin, TypeScript, Go oder Rust – die Schnittstelle bleibt immer gleich:
Kein Wechsel zwischen mvn, pnpm, cargo und go in der CI-Pipeline. Ein Befehl für alles.
Toolchain vereinheitlichen mit Mise
Bevor Nx orchestrieren kann, braucht jede Sprache ihre Toolchain. In der Welt der 15 Repositories sah das so aus:
nvmfür Node.js-VersionenSDKMANfür Java und Mavenrustupfür Rustgoenvfür GoManuell installierte CLIs für
kubectl,helm,pulumi, die Exoscale CLI, und ein halbes Dutzend weitere Tools
Fünf verschiedene Versionmanager, fünf verschiedene Konfigurationsformate, fünf Stellen an denen etwas schiefgehen kann. Und es geht regelmäßig etwas schief: Ein Entwickler hat lokal Node 18, der CI-Server Node 24. Oder jemand hat vergessen, SDKMAN zu aktualisieren und baut mit einer alten Java-Version. Die Fehler sind dann subtil und kosten Stunden.
Mise löst das radikal: Eine einzige Datei im Repository-Root definiert alle Tool-Versionen.
Ein einzelnes mise install und der gesamte Technologie-Stack steht. Alles in den exakt gleichen Versionen, auf jedem Rechner, in jeder CI-Pipeline.
Das klingt nach einem kleinen Detail, aber in der Praxis eliminiert es eine komplette Kategorie von Problemen. "Funktioniert auf meinem Rechner" gibt es nicht mehr, weil es keinen Unterschied zwischen "meinem Rechner" und dem CI-Server gibt.
Mehr als ein Versionmanager: Infrastruktur-Zugang
Mise verwaltet nicht nur Tool-Versionen. Über Environment-Variablen und Tasks wird es zum zentralen Einstiegspunkt für die gesamte Entwicklungsumgebung – inklusive Cloud-Zugang.
In unserem Fall läuft die gesamte Infrastruktur auf Exoscale, einem europäischen Cloud-Anbieter mit Rechenzentren in Österreich. Mise konfiguriert den Zugang zu allen Exoscale-Services:
Warum AWS-Credentials für Exoscale? Weil Exoscale S3-kompatiblen Object Storage (SOS) anbietet. Standard-AWS-Tools wie die AWS CLI, das AWS SDK und Pulumi funktionieren direkt – man muss nur den Endpoint auf Exoscale zeigen lassen. Dazu mehr im Abschnitt über Pulumi.
Die eigentlichen Secrets liegen in einer mise.local.toml, die nicht ins Git eingecheckt wird:
Für den Kubernetes-Zugang verwenden wir keinen statischen Token oder ein exportiertes Zertifikat, sondern einen Exec Credential Provider. Das kubeconfig.yaml ruft bei jedem kubectl-Befehl die Exoscale CLI auf, die dynamisch ein kurzlebiges Credential erzeugt:
Der Vorteil: Kein langlebiges Token, das rotiert werden muss. Solange die Exoscale-Credentials in mise.local.toml gültig sind, funktioniert kubectl – die exo CLI übernimmt die Authentifizierung im Hintergrund.
Mise kann neben Tool-Versionen auch Tasks definieren – Shell-Skripte, die direkt in der mise.toml leben. Wir nutzen das, um aus den Exoscale-Credentials eine AWS-kompatible Credentials-Datei zu erzeugen:
Ein mise run generate-aws-creds liest die Exoscale-Secrets aus mise.local.toml und schreibt sie in das AWS-Credentials-Format. Das Ergebnis:
Damit funktionieren aws s3 ls, Pulumi, und alle S3-kompatiblen Tools gegen Exoscale.
Das Onboarding eines neuen Entwicklers sieht jetzt so aus:
Statt Stunden dauert das Setup jetzt Minuten.
Nx als polyglotter Orchestrator: Die Konfiguration im Detail
Das klingt in der Theorie elegant. Aber wie sieht die tatsächliche Konfiguration aus? Nx muss schließlich verstehen, welche Dateien zu welchem Projekt gehören – und was eine Änderung an einer pom.xml von einer Änderung an einer package.json unterscheidet.
Das Problem mit npm-Lock-Dateien
Ohne spezielle Konfiguration passiert Folgendes: Ein Frontend-Entwickler updated ein npm-Paket. Die pnpm-lock.yaml ändert sich. Nx markiert daraufhin alle Projekte als betroffen – auch die Go-Services, die Rust-Tools und die Spring Boot APIs, die mit npm nichts zu tun haben. Der gesamte Monorepo-Vorteil ist dahin: Alles wird neu gebaut.
Die Lösung sind Named Inputs – sprachspezifische Definitionen, die Nx sagen, welche Dateien für welche Projektkategorie relevant sind:
Der entscheidende Unterschied: Bei JVM, Go und Rust steht "externalDependencies": [] – eine leere Liste. Das sagt Nx: "Dieses Projekt hat keine npm-Abhängigkeiten. Änderungen an pnpm-lock.yaml sind irrelevant." Nur bei TypeScript-Projekten fehlt dieser Eintrag, weil dort npm-Paketänderungen tatsächlich den Build beeinflussen.
Ergänzend dazu eine Plugin-Konfiguration, die Nx anweist, die pnpm-Workspace-Struktur zu analysieren:
Das auto-Setting sorgt dafür, dass Nx die pnpm-workspace.yaml parst und nur Projekte als betroffen markiert, die tatsächlich im pnpm-Workspace registriert sind. Go-, Rust- und JVM-Projekte stehen dort nicht – also werden sie von npm-Änderungen nicht berührt.
Projekt-Konfiguration: Gleiche Struktur, andere Sprache
Nx erkennt JavaScript-Projekte automatisch über deren package.json. Für nicht-JavaScript-Projekte legt man eine project.json im Projektverzeichnis an – eine einfache JSON-Datei, die Nx sagt: "Hier ist ein Projekt, und so wird es gebaut." Das ist der gesamte Aufwand, um ein Maven- oder Cargo-Projekt in Nx zu integrieren.
Die Struktur ist immer gleich – nur die Befehle und Inputs unterscheiden sich je nach Sprache. Zwei Platzhalter tauchen dabei immer wieder auf: {projectRoot} zeigt auf das Verzeichnis des aktuellen Projekts (z.B. jvm/backend-api/), {workspaceRoot} auf das Monorepo-Root.
Ein Spring Boot API Projekt:
Ein Rust Projekt:
Die Semantik ist überall identisch: inputs definiert, welche Dateien den Cache invalidieren. outputs definiert, welche Verzeichnisse gecacht werden. dependsOn definiert, was vorher laufen muss. Es ist egal, ob dahinter mvn, cargo, go oder pnpm ausgeführt wird.
Auch das Docker-Packaging ist ein Nx Target. Es hängt vom build ab und wird in der CI-Pipeline nur auf master- und release-Branches ausgeführt:
Zwei Tags pro Image: master (wird überschrieben) und master-1fa4666 (unveränderlich). Das ist wichtig für die Deployment-Strategie – dazu gleich mehr.
Shared Libraries über Sprachgrenzen
Ein Monorepo entfaltet seinen vollen Wert, wenn Code und Definitionen projektübergreifend geteilt werden. In unserem Setup gibt es zwei Patterns, die diesen Vorteil konkret machen.
Pattern 1: Shared Library innerhalb einer Sprache
Mehrere Spring Boot Services teilen sich eine Bibliothek. Ohne Monorepo bedeutete das: Eine separate Bibliothek in einem eigenen Repository, mit eigenem Versionszyklus, eigener CI-Pipeline, und manuellen Updates in jedem Consumer-Repo.
Im Monorepo liegt die geteilte Bibliothek einfach neben den Services:
Die Consumer-Services binden die Bibliothek als ganz normale Maven-Dependency ein. Die Version bleibt dauerhaft auf 0.0.0-SNAPSHOT – es gibt keinen Release-Zyklus für die Library, weil sie nie separat veröffentlicht wird. Im Monorepo wird immer der aktuelle Stand gebaut:
Bewusst kein Maven Reactor
Ein naheliegender Ansatz wäre, alle JVM-Projekte in ein Maven Multi-Module-Projekt (Reactor) zu packen – mit einem übergeordneten pom.xml, das alle Module kennt. Wir haben uns bewusst dagegen entschieden.
Der Grund: In einem polyglotten Monorepo ist Maven nur eine von fünf Build-Toolchains. Ein Reactor würde die JVM-Projekte in eine eigene Abhängigkeitsstruktur pressen, parallel zu dem Graphen, den Nx bereits verwaltet. Das Ergebnis wären zwei sich überschneidende Systeme – Maven Reactor für JVM-interne Abhängigkeiten, Nx für alles andere. Das wird schnell unübersichtlich.
Stattdessen sind alle JVM-Projekte eigenständige Maven-Projekte ohne gemeinsames Parent-POM. Die Abhängigkeiten zwischen ihnen werden ausschließlich über Nx gemanagt:
In der CI-Pipeline sorgt Nx dafür, dass mvn install auf der Bibliothek läuft, bevor die abhängigen Services gebaut werden. Lokal ist das oft gar nicht nötig: IDEs wie IntelliJ sind intelligent genug, die Maven-Projekte im Monorepo zu erkennen und die Abhängigkeiten direkt aufzulösen – ohne dass die Bibliothek erst ins lokale Maven-Repository installiert werden muss. Man öffnet das Monorepo in IntelliJ, und die Source-Navigation zwischen Library und Consumer funktioniert sofort.
Der Effekt: Ändert ein Entwickler etwas an der Shared Library, werden in der CI automatisch alle abhängigen Services neu gebaut und getestet. In einem Commit. Keine manuellen Version-Bumps, keine vergessenen Repositories. Und lokal hat man trotzdem die volle IDE-Unterstützung mit direkter Navigation und Refactoring über Modulgrenzen hinweg.
Pattern 2: Cross-Language Code Generation über API-Specs
Hier wird es richtig spannend – und hier zeigt sich der größte Vorteil gegenüber separaten Repositories.
Das Szenario: Die Spring Boot API definiert eine OpenAPI-Spec (api.yaml) und ein GraphQL-Schema (schema.graphqls). Ein Go-Service generiert aus der OpenAPI-Spec seinen HTTP-Client. Das React-Frontend generiert aus dem GraphQL-Schema seine TypeScript-Typen.
In der Welt der 15 Repositories war der Ablauf: API-Entwickler ändert die Spec, committed, pushed. Dann schreibt er eine Nachricht im Team-Chat: "Hey, ich hab die API geändert, bitte generiert eure Clients neu." Vielleicht macht das jemand. Vielleicht vergisst es jemand. Vielleicht wird es erst bemerkt, wenn die Testumgebung bricht.
Im Monorepo passiert das automatisch. Die Spec-Dateien leben im Backend-Projekt:
Der Go-Service deklariert die OpenAPI-Spec als Input seiner Code-Generierung:
Das Frontend deklariert das GraphQL-Schema als Input:
Was passiert jetzt, wenn ein Entwickler die api.yaml ändert?
Nx erkennt über die inputs-Konfiguration, dass sich eine Datei geändert hat, die von mehreren Projekten referenziert wird. Die resultierende Kaskade:
backend-api:buildwird ausgelöst – die API selbst wird mit der geänderten Spec neu gebaut und getestet.go-service:codegenwird ausgelöst –go generateerzeugt einen neuen HTTP-Client aus der aktualisierten Spec.go-service:buildfolgt automatisch (weildependsOn: ["codegen"]) – der Go-Service wird mit dem neuen Client kompiliert. Passt der neue Client nicht zum bestehenden Code, bricht der Build hier ab.frontend:codegenwird ausgelöst – die TypeScript-Typen werden aus dem aktualisierten Schema generiert.frontend:buildfolgt automatisch – das Frontend wird mit den neuen Typen kompiliert. Typescript-Fehler werden sofort sichtbar.
Alles in einem git push. Kein manuelles "Bitte generiere die Clients neu" in einem Slack-Channel. Kein vergessenes Repository, das noch die alte Spec-Version verwendet. Wenn der Build grün ist, sind alle Clients synchron. Wenn er rot ist, weiß man sofort, wo die Inkompatibilität liegt.
Das ist der Unterschied, den ein Monorepo macht: Die API-Spec ist die Single Source of Truth, und das Build-System stellt sicher, dass sich kein Konsument davon entkoppeln kann.
Affected Detection: Nur bauen was sich ändert
Der größte Performance-Gewinn kommt von der Affected Detection. Das Prinzip ist einfach: Statt bei jedem git push alle 15 Projekte zu bauen und zu testen, ermittelt die Pipeline exakt, welche Projekte von den Änderungen im aktuellen Commit betroffen sind.
In einem typischen Arbeitstag ändern sich vielleicht zwei oder drei Projekte. Ohne Affected Detection baut die Pipeline trotzdem alle 15 – inklusive der Rust-Tools und Go-Services, die seit Wochen nicht angefasst wurden. Das kostet Zeit und CI-Ressourcen.
Die Logik in der Pipeline:
Was macht nx show projects --affected? Nx vergleicht den aktuellen Stand mit dem Base-Commit und ermittelt, welche Dateien sich geändert haben. Dann schaut es in die inputs-Konfiguration jedes Projekts und prüft, ob die geänderten Dateien relevant sind. Zusätzlich berücksichtigt es den Abhängigkeitsgraph: Wenn sich die Shared Library ändert, sind automatisch auch alle Services betroffen, die davon abhängen.
Das Marker-File-Pattern (touch affected/{projekt}) erzeugt eine Datei pro betroffenem Projekt im Filesystem. Das hat sich in der Praxis bewährt, weil diese Marker in späteren Pipeline-Steps gelesen werden können – etwa um zu entscheiden, welche Docker-Images gebaut und gepushed werden müssen.
Der Unterschied in Zahlen in der CI-Pipeline
Szenario | 15 Repos (vorher) | Monorepo (nachher) |
|---|---|---|
Änderung an einem einzelnen Projekt | ~5 Min (einzelner Build) | ~5 Min (nur dieses Projekt) |
Änderung an Shared Library | ~40 Min (abhängige Repos manuell updaten) | ~10 Min (automatisch, parallel) |
Dependency Update (npm) | ~60 Min (alle Node-Repos) | ~10 Min (nur betroffene TS-Projekte) |
Nx Cache Hit | nicht möglich | ~30 Sek (nichts wird gebaut) |
Der Monorepo-Build ist in den meisten Szenarien schneller, weil er weniger baut – obwohl er mehr Projekte enthält.
Caching-Strategie
Affected Detection bestimmt, welche Projekte gebaut werden. Caching bestimmt, ob sie tatsächlich gebaut werden müssen.
Nx berechnet für jedes Target einen Hash über alle Inputs: Quelldateien, Konfigurationsdateien, Abhängigkeiten. Wenn der Hash identisch ist zum letzten erfolgreichen Build, wird das gecachte Ergebnis verwendet – der Build-Befehl wird gar nicht ausgeführt.
In der CI-Pipeline werden neben dem Nx-Cache auch sprachspezifische Caches konfiguriert, damit nicht bei jedem Lauf alle Maven-Artefakte oder npm-Pakete neu heruntergeladen werden:
Nicht alles wird gecacht. Docker-Builds sind bewusst ausgenommen, weil ein gecachtes Docker-Image dazu führen kann, dass eine veraltete Version deployed wird. Ebenso serve (Dev-Server) und clean – Targets, bei denen Caching keinen Sinn ergibt.
Remote Cache: Build-Ergebnisse teilen
Lokal und in der CI-Pipeline spart der Nx-Cache bereits viel Zeit. Aber der volle Hebel kommt mit einem Remote Cache: Build-Ergebnisse werden zentral gespeichert und über alle Entwickler und CI-Runs hinweg geteilt.
Das Prinzip: Entwickler A baut backend-api lokal. Das Ergebnis wird im Remote Cache gespeichert. Wenn Entwickler B – oder die CI-Pipeline – dasselbe Projekt mit denselben Inputs baut, wird das Ergebnis direkt aus dem Cache geholt. Bei 15 Projekten mit durchschnittlich mehreren Minuten Build-Zeit pro Projekt ist das ein enormer Zeitgewinn.
Nx bietet dafür Self-Hosted Remote Caching mit einem S3-kompatiblen Storage-Backend an. Und weil Exoscale SOS S3-kompatibel ist, schließt sich der Kreis: Der Remote Cache kann im selben Exoscale-Account liegen wie der Rest der Infrastruktur – kein externer Caching-Service, keine Daten die das Unternehmen verlassen.
Infrastructure as Code mit Pulumi auf Exoscale
Bisher ging es um Code, Build und Test. Aber ein Produkt muss auch irgendwo laufen. In unserem Fall läuft die gesamte Infrastruktur auf Exoscale – definiert als Infrastructure as Code mit Pulumi.
Warum Exoscale?
Exoscale ist ein europäischer Cloud-Anbieter mit Rechenzentren in Österreich und der ganzen EU. Für Projekte mit DSGVO-Anforderungen oder dem Wunsch nach Datensouveränität ist das ein entscheidender Vorteil gegenüber AWS, Azure oder GCP: Die Daten verlassen nie den europäischen Rechtsraum.
Was viele überrascht: Exoscale bietet eine vollständige Plattform, die alle Bausteine für eine moderne Cloud-Architektur liefert. Managed Kubernetes, S3-kompatibler Object Storage, Managed PostgreSQL, Container Registry – alles, was man für eine Produktionsumgebung braucht. Ohne die Komplexität von 200+ AWS-Services, aber auch ohne die Einschränkungen einfacher Hosting-Lösungen.
Warum Pulumi statt Terraform?
Pulumi definiert Infrastruktur in echten Programmiersprachen – in unserem Fall TypeScript. Das bedeutet: Keine neue DSL lernen, IDE-Unterstützung mit Auto-Complete, und die Möglichkeit, Schleifen, Bedingungen und Funktionen zu nutzen statt Copy-Paste.
Kubernetes: Exoscale SKS
Exoscale SKS (Scalable Kubernetes Service) ist ein vollständig verwalteter Kubernetes-Cluster. In Pulumi:
Zusätzlich können Anti-Affinity-Gruppen sicherstellen, dass die Nodes auf unterschiedlichen physischen Hosts laufen.
Object Storage: S3-kompatibel, aber europäisch
Exoscale SOS (Simple Object Storage) ist API-kompatibel mit AWS S3. Das ist der Schlüssel: Derselbe Code, dieselben SDKs, dieselben Tools – aber die Daten bleiben in Wien statt in Virginia.
In Pulumi verwenden wir den Standard-AWS-Provider. Der einzige Unterschied zu AWS: der Endpoint.
Die skip-Flags sind nötig, weil Exoscale kein AWS ist – es gibt keinen AWS Metadata Service und keine AWS-Regionen. Aber alles, was S3-Operationen betrifft (Upload, Download, Presigned URLs, Versioning), funktioniert identisch.
Derselbe Ansatz funktioniert auch lokal über die AWS CLI:
Managed PostgreSQL
Automatische Backups, IP-Filterung, Termination Protection – alles deklarativ in Pulumi definiert, versioniert in Git.
Pulumi State: Auch auf Exoscale
Ein oft übersehenes Detail: Wo liegt der Pulumi State – also der komplette Zustand der Infrastruktur? Standardmäßig bei Pulumi Cloud (US-basiert) oder in einem AWS S3 Bucket.
In unserem Setup liegt der State in einem Exoscale SOS Bucket:
Damit ist die Kette vollständig souverän: Der Code liegt in Europa, die Infrastruktur-Definition liegt in Europa, der Infrastruktur-State liegt in Europa, und die laufenden Services liegen in Europa. Kein einziger Datenpunkt verlässt den europäischen Rechtsraum.
Von Git Push bis Kubernetes: Die vollständige Pipeline
Jetzt das Gesamtbild. Was passiert, wenn ein Entwickler seinen Code pushed – bis die Anwendung auf dem Kubernetes-Cluster in Wien läuft?
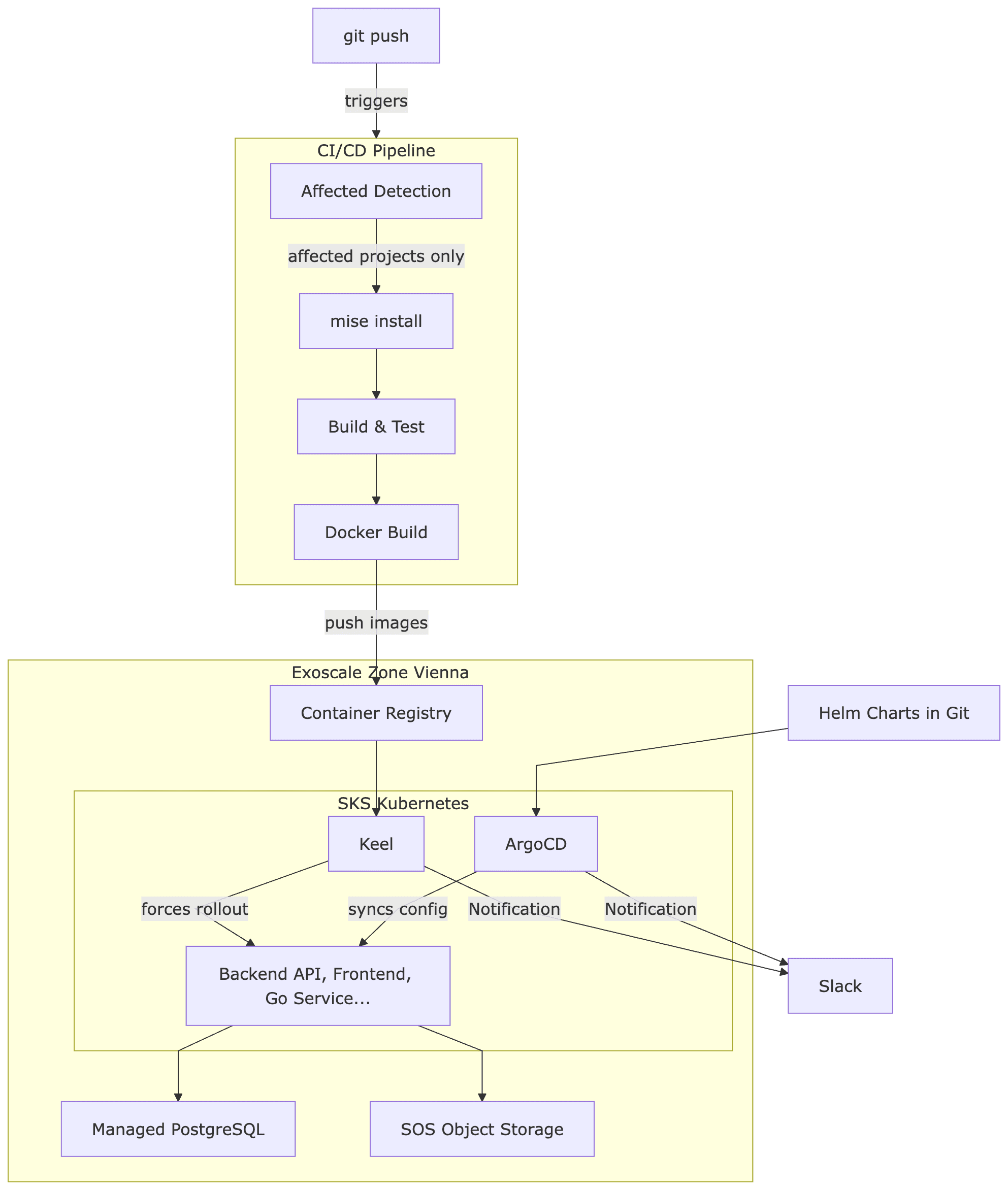
Schritt für Schritt
1. Git Push: Ein Entwickler pushed auf den master-Branch.
2. Affected Detection: Die CI-Pipeline ermittelt per nx show projects --affected, welche der 15 Projekte betroffen sind. Wurden nur Frontend-Dateien geändert, wird kein einziger JVM- oder Go-Build angestoßen.
3. Mise Install: Alle benötigten Tools werden über Mise installiert. Dank CI-Cache dauert das nach dem ersten Lauf nur Sekunden.
4. Build & Test: Nx führt lint, build und test parallel für alle betroffenen Projekte aus. Nicht betroffene Projekte werden übersprungen. Gecachte Ergebnisse werden wiederverwendet.
5. Docker Build & Tag: Nur für betroffene, containerisierte Services werden Docker Images erstellt. Jedes Image bekommt zwei Tags: den Branch-Namen (master) und eine eindeutige Version (master-1fa4666). Der Branch-Tag wird bei jedem Build überschrieben, der Commit-Tag ist unveränderlich.
6. Push zur Exoscale Container Registry: Die Images werden in die private Container Registry auf Exoscale gepushed. Exoscale bietet eine eigene Registry – kein Docker Hub, kein AWS ECR nötig.
7. Keel erkennt neue Images (Test/Staging): Hier kommt ein wichtiges Detail: In der Test-Umgebung zeigen die Kubernetes-Deployments auf einen gepinnten Tag – z.B. image: backend-api:master. ArgoCD allein würde kein Update auslösen, weil sich der Tag in den Helm Charts nicht ändert – es ist immer noch master. Aber der Inhalt hinter dem Tag ist neu. Keel löst genau dieses Problem: Es überwacht die Container Registry, erkennt dass master auf einen neuen Digest zeigt, und erzwingt einen Rollout im Cluster.
8. ArgoCD für Konfiguration und Production: ArgoCD überwacht ein GitOps-Repository mit Helm Charts. Infrastruktur-Änderungen – neue Environment-Variablen, geänderte Ressourcen-Limits, zusätzliche Services – werden über Git-Commits gesteuert. Für Production werden dort auch explizite Image-Versionen gesetzt (z.B. image: backend-api:master-1fa4666), sodass Deployments bewusst und nachvollziehbar erfolgen.
Zwei Cluster – Test (automatisch via Keel) und Production (explizite Versionen via ArgoCD) – stellen sicher, dass jede Änderung zuerst automatisch in der Testumgebung validiert wird, bevor sie bewusst in Production promoted wird.
Das Ergebnis
Nach der Konsolidierung von 15 Repositories in ein polyglottenes Monorepo:
Build-Zeiten um 60-80% reduziert – nicht durch schnellere Hardware, sondern weil Affected Detection und Caching nur das bauen, was sich tatsächlich geändert hat.
Onboarding von Stunden auf Minuten verkürzt –
git clone,mise install,pnpm install, fertig. Kein "Welche Java-Version brauche ich nochmal?" mehr.API-Änderungen können nicht vergessen werden – ändert sich die OpenAPI-Spec, werden automatisch alle Clients in Go und TypeScript neu generiert. Der Build bricht, bevor inkompatibler Code in der Testumgebung landet.
Atomic Changes über Sprachgrenzen – ein Commit kann gleichzeitig die API, den Go-Client und das TypeScript-Frontend ändern. In 15 separaten Repos wären das drei koordinierte Pull Requests gewesen.
Vollständig europäisch souverän – vom Pulumi State über die Container Registry bis zur Datenbank läuft alles auf Exoscale in Wien. Kein Datenpunkt verlässt den europäischen Rechtsraum.
Fazit
Die Kombination aus Nx, Mise, Pulumi und Exoscale ermöglicht einen vollständig souveränen Entwicklungs- und Betriebsstack:
Nx orchestriert den Build über alle Sprachen hinweg – egal ob Kotlin, TypeScript, Go oder Rust.
Mise vereinheitlicht die gesamte Toolchain in einer Datei – inklusive Cloud-Zugang zu Exoscale.
Pulumi definiert die Infrastruktur als TypeScript-Code – nachvollziehbar, versioniert, reviewbar.
Exoscale liefert die europäische Cloud-Plattform – mit Managed Kubernetes, S3-kompatiblem Storage, PostgreSQL und Container Registry.
Kein AWS. Kein Azure. Kein Google Cloud. Alles in Europa, alles DSGVO-konform, alles aus einer Hand.
Wir unterstützen Unternehmen bei der Umsetzung genau solcher Architekturen – von der Monorepo-Migration über Infrastructure as Code bis zum laufenden Betrieb auf der souveränen EU-Cloud. Mehr erfahren →


